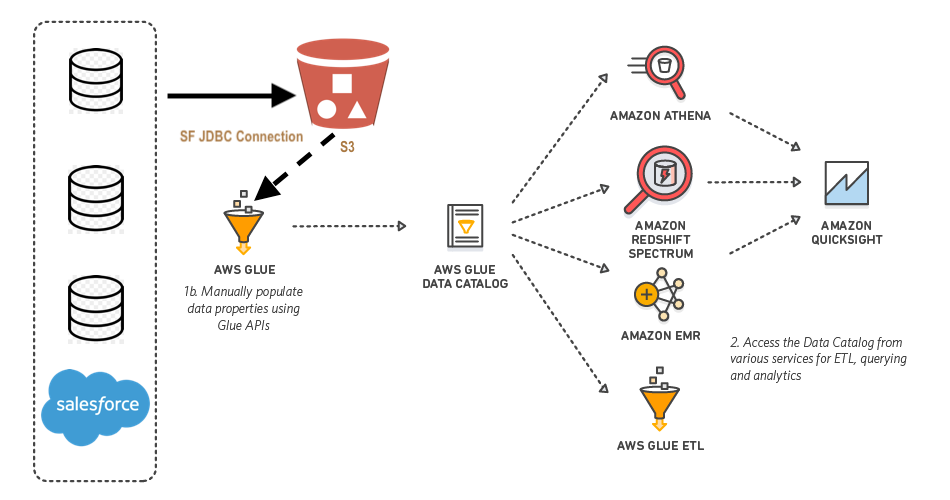
AWS Glue is a fully managed extract, transform, and load (ETL) service. It helps individuals and organizations to move data from a wide range of data stores to the AWS cloud.
Glue connects through JDBC (software component enabling connection) to Postgres, MySQL, Redshift, and Aurora databases. One can also use DataDirect Connect, a suite of Type 4 JDBC drivers for high-performance Java database connectivity, to bring other data sources in AWS Glue.
AWS Glue is serverless and does not require any infrastructure provisioning. The ETL jobs run in a fully managed and scalable spark environment. One can automatically generate a Glue job code, as it can craw data sources, identify schemas and data formats by itself. Recently, Datalya data science consultants completed the integration of Salesforce and AWS Glue for predictive analytics in the financial services business. In this article, we will demonstrate the step by step process for a wider community of data scientists.
1. Sign up for Salesforce (Trial)
- Go to https://www.salesforce.com
- Sign up for a trial account.
- Note down your username, password, and security token. You will need to use it inside Spark code.
2. Download DataDirect Salesforce JDBC Driver
- Download DataDirect Salesforce JDBC driver from here.
- Extract the compressed file and Execute the JAR package with the following command in terminal or just by double-clicking on the JAR package.
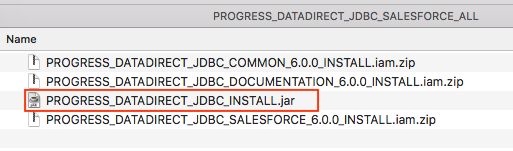
*java -jar PROGRESS_DATADIRECT_JDBC_SF_ALL.jar* - It will launch an interactive Java installer and let you install the Salesforce JDBC driver.
3. Upload DataDirect Salesforce Driver to Amazon S3
- Navigate to the location/directory where you installed the DataDirect JDBC drivers.
- Under that directory, locate the DataDirect Salesforce JDBC driver file, named sforce.jar.
- Upload sforce.jar to the AWS S3 bucket.
4. Create an IAM role for AWS Glue:
- Go to https://console.aws.amazon.com/iam/
- In the left navigation pane, choose Roles.
- Choose Create role.
- For role type, choose AWS Service, find and select Glue, and choose Next: Permissions.
- On the Attach permissions policy page, choose the policies that contain the required permissions; for example, the AWS managed policy AWSGlueServiceRole for general AWS Glue permissions, and the AWS managed policy AmazonS3FullAccess for access to Amazon S3 resources.
- Then choose Next: Review.
5. Create AWS Glue Job
- Go to AWS Console, search AWS Glue and click on it
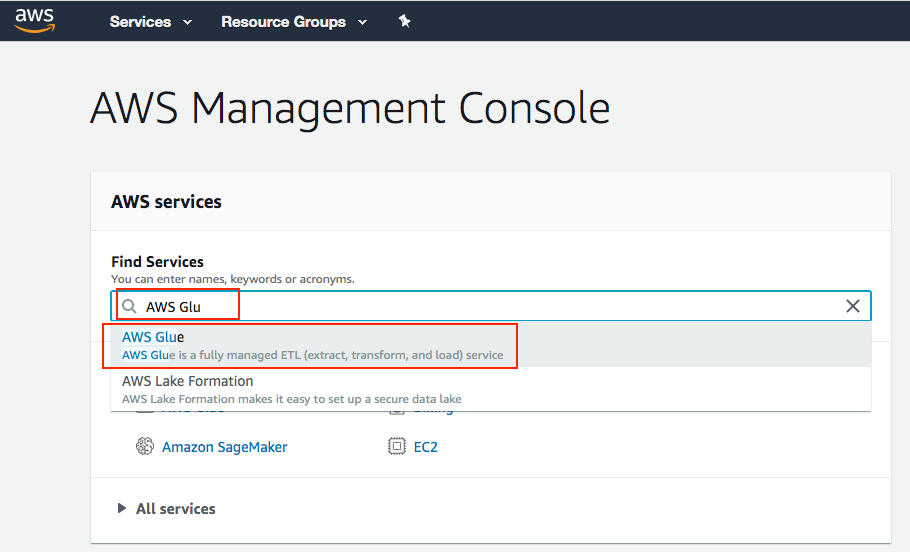
- Add Job button to create a new job as shown below:

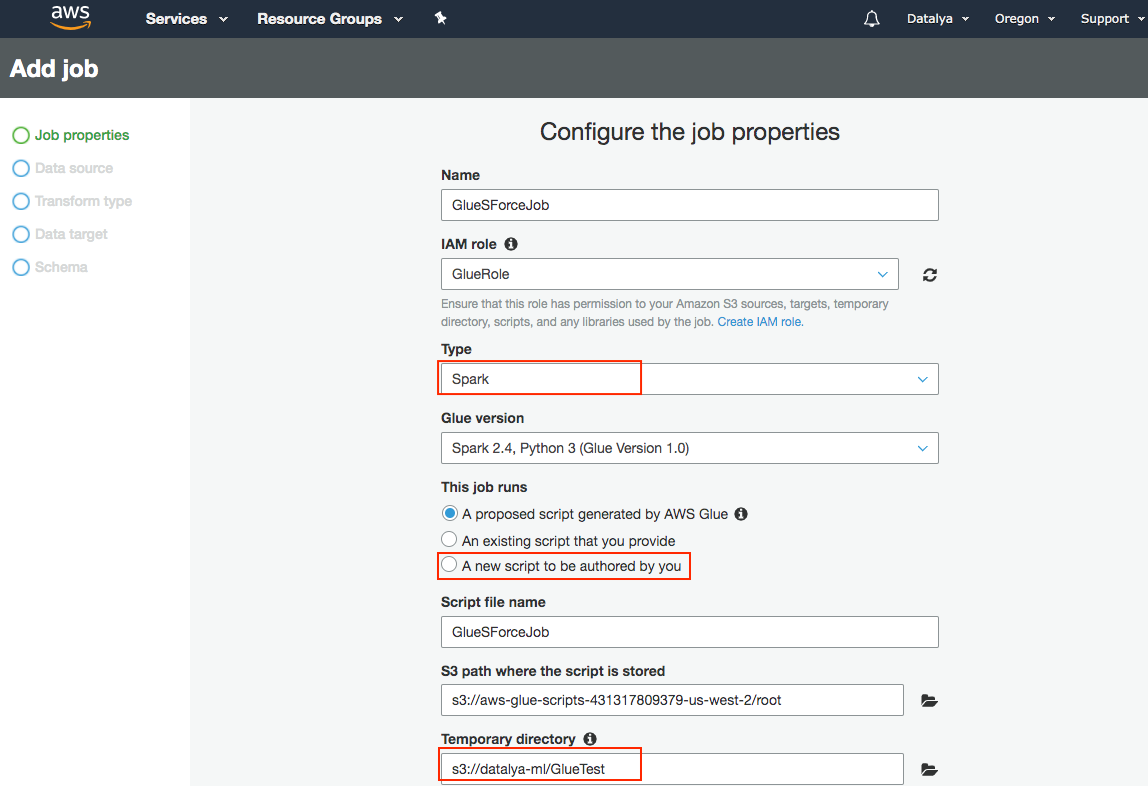
- Fill in the name of the Job
- Choose the name of newly created IAM role from the dropdown
- Choose A new script to be authored by you under This Job runs options.
- Give a name for your script and choose a temporary directory for Glue Job in S3.
- For Dependent Jars path, choose the sforce.jar file in your S3. Your configuration should look as shown below.
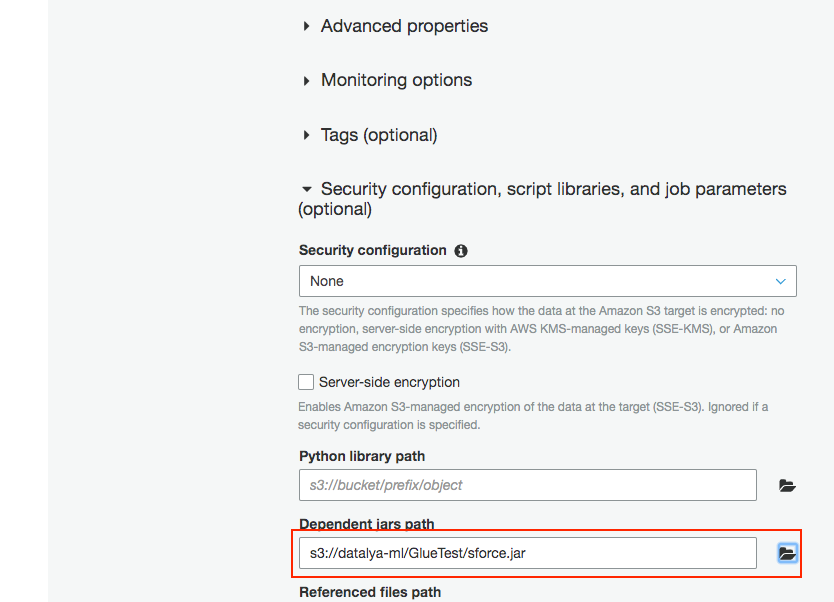
- Click the Next button
- Click on Next, review your configuration, and click Finish to create the Job.
You should now see an editor to write a Python script for the Job. Here, you write your custom Python code to extract data from Salesforce using DataDirect JDBC driver and report it to S3 or any other destination.
You can use this code sample shown below:
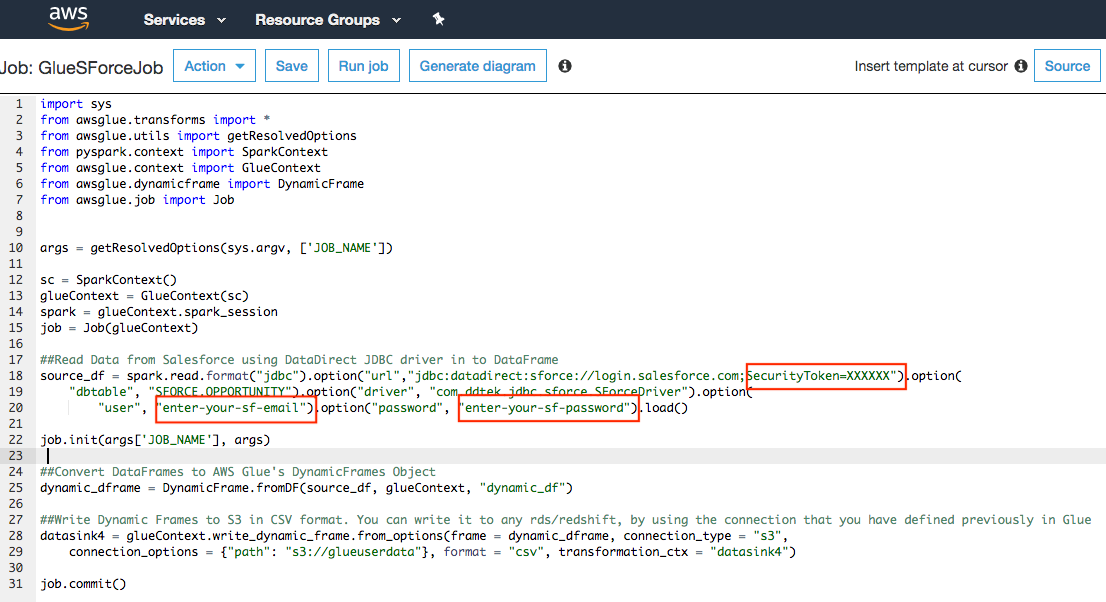
6. Run Glue Job
Finally, save the Job and then run it. It will extract the data from Salesforce using DataDirect JDBC driver and write it to S3 in a CSV format.