Over the last decade, machine learning has made huge strides in terms of increased prediction accuracy and more comprehensive. While consulting for machine learning solution development, our clients often ask questions around the role of convolution in deep learning.
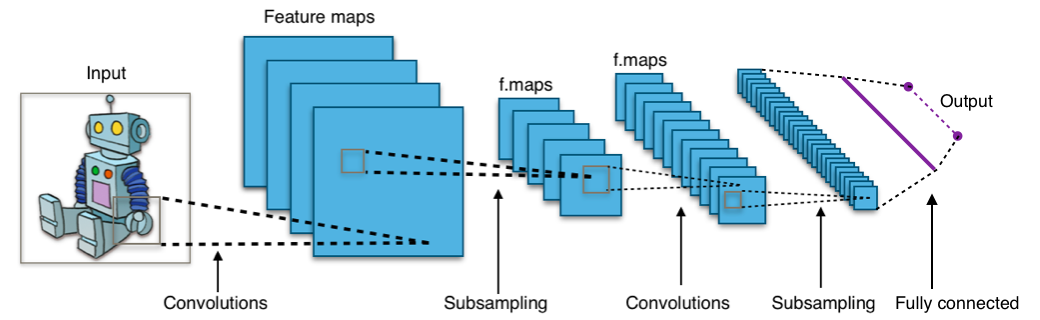
In addition to the availability of data, and cheap compute and storage, the key driving factor behind this success has been advancement in deep learning algorithms like convolutional neural networks (CNN). CNN is one of the most popular and powerful deep learning algorithms in computer vision.
CNN drivers its strength from convolution layers to learn essential features on its own. Convolution layers provides us with two significant advantages over fully connected layers;
1. Parameter Sharing
Let's say we have 32x32x3 input image and convolve it with six 5x5 filters. That would results in an output of dimensions 28x28x6 . Here, the convolution operation involves 152 parameters, where each filter is contributing 25 filter values and 1 bias value.
On the contrary, a fully connected layer will require around 14 million parameters to calculate 28x28x6 activation matrix from 32x32x3 input matrix.
The reason the convolutional layer has fewer parameters is parameter sharing, meaning a feature detector that is useful in one part of the image is probably also useful in another part of the image. This applies to both low-level features, like edges, and high-level features like the eye of the cat.
2. Sparsity of Connections
In the convolution layer of the convolutional neural network (CNN), each output value depends on a small number of input values, known as the sparsity of connections. The sparsity of connections inhibits overfitting during network training and keeps the size of the neural network significantly small at the same time, not affecting baseline accuracy.