Decision trees are one of the most used supervised learning algorithms. Though decision trees are very intuitive, data science consultants at Datalya often do get asked how decisions trees work.
Decision trees predict the future outcome of a process by asking a series of dependent questions. Given historical data of the process, the decision tree learns the best set of questions to ask and the sequence of those questions. The most important question is asked first and then next important one and so on, making a decision tree where the first question is at root and terminals or leaves are outcomes and in between are split/decision nodes. The intuition of decision trees is very similar to the decision making of us human beings.
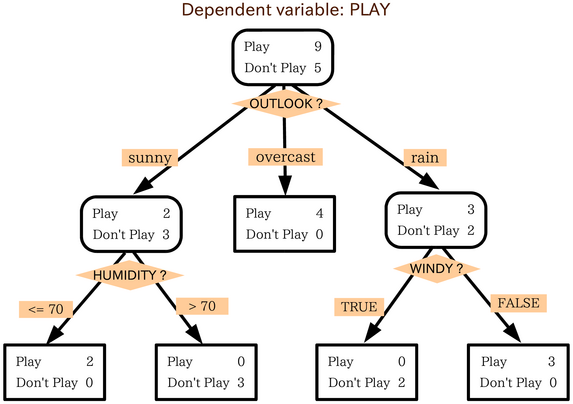
Imagine every Saturday you go out to play golf based on following weather factors;
- Outlook: sunny, overcast, rain
- Temperature: hot, cool, mild
- Humidity: high, normal
- Wind: weak, strong
Imagine, you have been keeping a record of the above factors along with outcome (i.e., whether there was a play or no-play) for the last 14 weeks. Now you want to build a decision tree model so that every Saturday, you can feed values of outlook, temperature, humidity, and wind to the model and rightly predict whether you might go for play or no-play.
Although in our example, the outcome variable is categorical, decision trees can also handle real-valued. That means we can build models of both regression and classification decision trees.
Technically speaking, a decision tree consists of three types of nodes;
- Root node is the top node and does not have any parent.
- Split node also referred to as decision node, has one parent, and one or more child nodes.
- Leaf or terminal node holds class label
How do we build a decision tree using labeled training data?
Given labeled training data, how do we learn a decision tree? Decision trees are built by defining a set of rules (questions) against input attributes (X) of training data. Each feature (x) together with associated rule makes a decision node at which we split data into two or more further branches. The top split node is called root.
Imagine we are sitting at the root and have to make a split on data. How do we decide which attribute is best to do that split? A perfect feature would ideally split training examples into subsets that are either all negative or all positive.
How do we measure the strength of an attribute? We often use following metrics for that;
- Information gain measures worth of an attribute in terms of purity of the split.
- Entropy is a measure of uncertainty or randomness of a set of node objects. High information gain would always result in lower entropy.
- Cost function measures cost we have to pay for accuracy
In our golf play decision, the split at the root node would be done at attribute x if x is most information among all features.
Pros and Cons:
Decision trees are straightforward and easy to interpret. Their visual representation can help us to understand the strength and relationship among attributes. Decision trees work with both categorical and numerical features and can handle missing values.
Decision trees are often biased towards attributes with fewer levels or unique values. They can even overfit (giant tree) if training data is noisy. Additionally, a large number of features may lead to a detailed decision tree.