Dr. Rizz
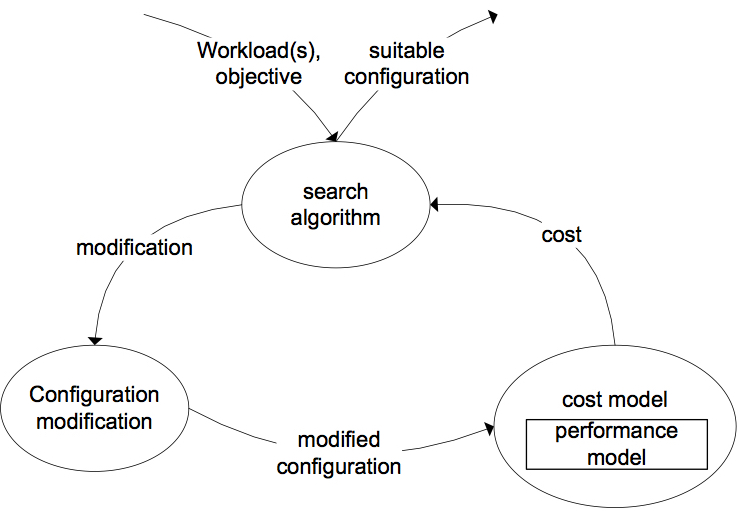
In my PhD, I propose a novel framework for resource provisioning in a public cloud environment. The high-level architecture of the provisioning framework is shown in Fig 1. The framework employs a search algorithm to explore the search space. Given a set of workloads and an objective, a search algorithm looks for a suitable resource configuration. At each iteration, the search algorithm chooses a suitable modification on the current configuration. The modified configuration is evaluated using a cost model. The cost model, in turn, employs a performance model to predict the expected behavior of workloads on the modified configuration. The cost model passes a cost value back to the search algorithm. Then, the algorithm decides whether to keep exploring the search space or to flag the evaluated configuration as a suitable one. The chosen configuration is enacted and executed in a public cloud. Let us look at each component in some detail.
Performance Model: A performance model is required to forecast the behaviour of a workload execution at a multi-partition data service. Initially, I considered an analytical performance model, however, I experienced highly inaccurate forecasts in the response times. This is because the analytical models do not capture the complex effects of the concurrently executing requests on the servers, which are amplified by the variance in the cloud. Furthermore, the analytical modeling techniques are notoriously hard to evolve with the system. Increasingly the research community is using statistical oriented performance modeling for database management and multitier systems. A subset of statistical-based performance models account for the impact of the interactions among the concurrently executing request types on performance. Therefore, I consider and find a statistical-based approach in building a performance model to be appropriate.
Cost Models: Executing a configuration in a public cloud results in a dollar-cost expense. Such an expense is a function over resource costs. I extend this expense with penalties for violations of service level agreements (SLAs) defined over the workload. There are primarily three types of resources needed to execute a workload in a cloud that offers its infrastructure-as-a-service (IaaS): (a) compute, (b) storage, and (c) network. The cost function for the pay-as-you-go pricing scheme is stated as:
\$(configuration) = \$(compute) + \$(storage) + \$(network) + \$(penalties),
where $ represents dollar-cost of resource usage, penalties or the configuration. This is also the objective function, which needs to be minimized. I find that my previous cost model is adequate for data analytics workloads operating over a single partition. However, in this model, I assume a constant cost for network, provide partial storage cost, and I account for penalties only over response times. I extend this model to account for any analytical, transactional or hybrid workloads, and model costs for all the resources used. I instantiate the cost model for the Amazon cloud, and experimentally evaluate the impact of key factors on the accuracy of the model.
Space Search: The problem of finding the global optimum or the least costly configuration is NP-hard in the general case. The space of possible configurations is very large and heuristics must be used to prune the search space. I have developed algorithms that search for the minimal dollar-cost configuration. These algorithms use different heuristics to explore different parts of the search space: (a) greedy, (b) pseudo genetic algorithm (pseudo-GA), and (c) tabu search. Further, the algorithms employ an adaptive look-ahead window to avoid being trapped in a local minimum. The window is a function of number of workloads, and number of iterations to find the last minimum. I find that the greedy algorithm always selects amongst a small subset of modifications, and often cycles between them. In contrast, the pseudo-GA chooses a random modification at every iteration amongst all possible modifications. In contrast to pseudo-GA, the tabu search algorithm uses tabu constructs to select the modifications systematically. I find that tabu search outperforms pseudo-GA and the greedy algorithm in evaluation, and gives provably optimal costs in the limited cases considered.
My doctoral work integrates dollar-cost with workload execution with associated SLAs, and optimizes for minimal dollar cost. I used machine learning and analytical modeling to build performance and cost models. Meanwhile, the algorithms were developed in java. The work has been validated in the Amazon public cloud. I published a summary in the technical report openly available for public reading.