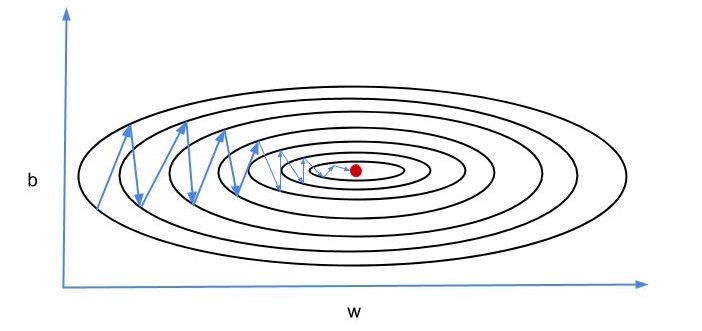
Gradient descent is commonly used search algorithm in machine learning. We use it to learn parameters of prediction model. One of the problems with straightforward gradient descent is that it oscillates too much on vertical axis (as show in above image). This oscillations slows down the convergence to minimum (the red dot).
What we want is less oscillation on vertical axis and faster march on horizontal axis towards the minimum. Consequently this would result into faster learning and convergence to the minimum of energy landscape.
How do we achieve this objective? Gradient descent with momentum is one of many possible ways to do that. Gradient descent with momentum is an optimization algorithm which relies on exponentially weighted averages - applied (exponentially decreasing) weighting factors to older data points.
Here is how we implement gradient descent with momentum:
On each iteration of batch or mini-batch gradient descent, first compute derivatives, $dW$ and $db$, and then get exponentially weighted averages as following
$$v_{dW} = \beta v_{dW} + (1-\beta)dW$$
$$v_{db} = \beta v_{db} + (1-\beta)db$$
This will add another hyperparameter $\beta$ to learning algorithm. Typically value 0.9 is used for $\beta$ to take average of last 10 iterations' gradients. There is no need for bias-correction as the bias will disappear after few iterations of gradient descent. In equations 1 and 2 above, the derivatives represent acceleration whereas momentum terms are velocity. $\beta$ term can be seen as friction.
Now we can update the weights using exponentially weighted averages (than usual derivatives);
$$W := W - \alpha V_{dW}$$
$$b := b - \alpha v_{db}$$
This will smooth out gradient descent and the vertical oscillations will average out to zero. As a consequence gradient descent will to converge quickly because it is not taking every step independent of previous ones. It is rather taking previous steps into account to gain momentum from them.